The data for this java application is from a web servers log file. The data is placed in a PostgreSQL database using a perl script that runs via cron four times a day.
The web server log data, while containing only nine pieces of information per access, can be viewed in a large number of desired contexts. This application was designed to be flexible enough to accomodate any hierarchy that can be indicated using a SQL statement.
Most 'explorer' style systems are comprised of two visual pieces, a left side tree and a right side table or list. In this application the tree is used to navigate a query's class hierarchy to a node that corresponds to a specific subsetting query.
Example:select A,B,C,D,t,u,v,w,x,y,z from tableAssume the uppercase columns represent some hierarchy and the lowercase
letters represent some measurement (metric) or other observational information.
The left hand tree presents a navigation through all the combinations of values
of A,B,C,D encountered in the results of the query. A node in the tree
represents a set of specific values alpha/beta/gamma/delta.The right
hand table shows the rows corresponding to the tree node; e.g. where
A=alpha and B=beta and C=gamma and D=delta.
Here is a screenshot of a Server, Year, Month, Day, Client hierarchy with corresponding access information for the selected node Year=2000 and month=10. Note: Even though the tree shows other sub-nodes of month 11, the selection is the level 2 10 value. The selected node drives what is shown in the table.
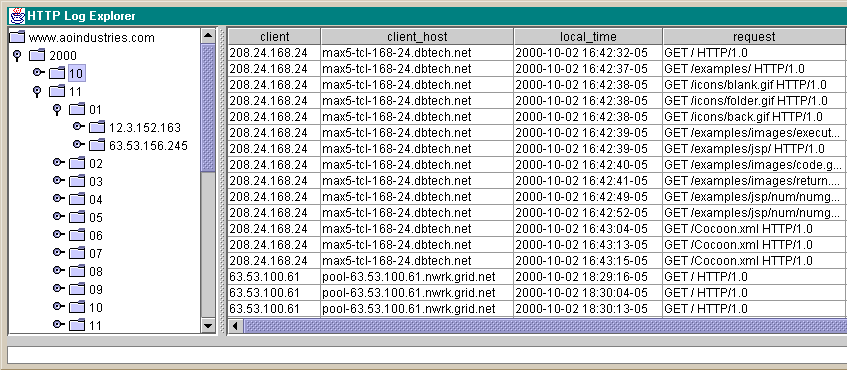
In my situation I only have a 56k modem network connection, so a query that returns thousands of rows would take a long time to transmit the results to the resultsSet in the java application. To a user, the application would appear to have died or froze.
Many 'explorer' systems that allow navigation through a large time consuming complex SQL query might typically perform the entire query and append to a where clause to restrict information returned to provide a tree nodes children or the matching rows of a selected node that are to be shown in the table. Oft times, the first levels of a query can be reduced to a simpler, faster executing query.
The http.log.Explorer addresses several concerns regarding low-speed access to the database tables.
I implemented a scheme that allows each level of the tree to obtain it's children using a hand optimised query. The additional query brainwork on the developers part pays off by maximizing information throughput. (Implementing the brainwork done to reduce a complex join to the simplest necessary query at a given hierarchical level could be the subject of another, very sophisticated, java class.) The offset for this gain is more load on the presumably faster database server.
Most queries to obtain the node values to show below a node selected to be expanded require knowledge of the values of the nodes to reach that node. This is the node path.
The application was developed using Sun's Forte for Java Community Edition
Explorer.java
The main program instantiates the tree and table
components in a grid bag layout so that the tree and table will resize when the
application frame is resized. It presents a database login dialog, attempts
connection to the database server, tells the tree what hierarchy it will
display and installs a TreeSelectionListener that responds to a node selection
by changing what rows and columns are shown in the table.
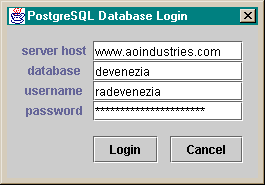
Login.java
Presents a dialog for obtaining values needed by
the JDBC driver manager when a database connection is to be made. Demonstrates
how an object can request focus when a form is created.
LoginInfo.java
An object used to transfer the values entered
in the Login dialog back to the dialog caller.
AbstractHierarchyLevelQueryModel
Template for delivering
information needed to render the tree hierarchy. This class is the crux of the
application.
getLevelCount() returns how deep the tree is.
childQuery()
returns the query that should be performed to determine child node
values.
tableQuery() returns the query that should be performed to obtain
data to show in the table when a node is selected.
Extensions of this class
must deliver valid queries for each level up to LevelCount.
Each
extension of this abstraction concretizes a specific hierarchy and the
(hopefully hand optimized) templated queries that should be performed to obtain
necessary data when a node is selected. Templated queries contain tokens that
represent tree node path values. Tokens are resolved in the resolve()
method.
Template rules:
A templated query is any valid SQL query,
that may conditionally contain node path level tokens. Each token encountered
is replaced with the value of the node level in the path to a node.
Node
path level tokens are indicated in the query using : n :, a colon
enclosed string of digits. :: is ignored (which is good since that is the
PostgreSQL typecast operator)
The node path level n can be specified
in either a absolute descending manner (n>0) or in a relative ascending
manner (n<0). Each token encountered is replaced with the value of the level
in the path to the node. The replacement is performed by the resolve()
method.
n < 0 represents the NODE's nth parent value.
n = 0
represents the NODE's value.
n > 0 represents the TREE's nth child value
in the path to NODE.
Note: the root node value is only obtainable using n
< 0 fashion.
y_m_d_inet_HierarchyModel
This extension of
AbstractHierarchyLevelQueryModel contains the templated queries that are used
by the HierarchyNodes. There is one templated query for each level of the tree.
The queries are stored in arrays. HierarchyNode uses this class to obtain
resolved queries for a given node at a given level using methods childQuery()
and tableQuery().
The node_childQueryTemplate demonstrates absolute descending
tokens.
The node_tableQueryTemplate demonstrates relatively ascending
tokens.
private String [] node_childQueryTemplate = {
"select distinct substr(local_time,1,4) from access"
, "select distinct substr(local_time,6,2) from access "
+ "where substr(local_time,1,4) = ':1:'"
, "select distinct substr(local_time,9,2) from access "
+ "where substr(local_time,1,7) = ':1:-:2:'"
, "select distinct id_value, client_inet from access, ids, client_inet "
+ "where substr(access.local_time,1,10) = ':1:-:2:-:3:' "
+ "and access.client_id = ids.id "
+ "and ids.id = client_inet.id "
+ "order by client_inet.client_inet"
};
private String [] node_tableQueryTemplate = {
"select * from access_log "
+ "order by local_time"
, "select * from access_log "
+ "where substr(local_time,1,4) = ':0:' "
+ "order by local_time"
, "select * from access_log "
+ "where substr(local_time,1,7) = ':-1:-:0:' "
+ "order by local_time"
, "select * from access_log "
+ "where substr(local_time,1,10) = ':-2:-:-1:-:0:' "
+ "order by local_time"
, "select * from access_log "
+ "where substr(local_time,1,10) = ':-3:-:-2:-:-1:' "
+ "and client = ':0:' "
+ "order by local_time"
};
HierarchyNode
An extension of DefaultMutableTreeNode. Each
instance is a node in a tree. Each node knows its value, depth and
HierarchyLevelQueryModel. Each node also has a reference to a JDBC statement
that can be used to execute queries. This class uses the
HierarchyLevelQueryModel to obtain the query to perform to obtain it's children
when getChildCount() is called for the first time. It also can deliver the
resolved queries of the HierarchyLevelQueryModel via it's getChildQuery() and
getTableQuery() methods.
ResultsDataModel
A generic extension of AbstractTableModel.
Given a JDBC statement handle, and a query to perform, a ResultSet is obtained
from the database. Some ResultSet meta information is placed in a vector, the
ResultSet row data is placed in a vector of vectors and the ResultsSet is
closed. getColumnName, getColumnCount (), getRowCount () and getValueAt()
methods are overridden to return information from the vectors.
psql_ResultsDataModel
A specialized runnable extension of
AbstractTableModel. This class is especially suited for low bandwidth
connections to the database server.
Since psql has special SELECT clauses
LIMIT and OFFSET a query can be continually reissued against the database
(incrementing the offset each time) until a ResultSet returns no rows. Each
limited set of results are added to a vector of vectors that are used to
deliver data to the table. In between the requeries the model performs a
fireTableRowsInserted() event so the table knows it should adjust it's
scrollbar and display more rows if necessary.
The class is run in a separate
thread when instantiated.thread = new Thread(this);
thread.start();
The class' run() simply fetches N rows at a time (using the
LIMIT and OFFSET feature of psql) until no rows are returned at a give
OFFSET.
If the underlying tables is prone to be updated during the repeated
queries, this class will be non-robust.
Please contact me if you are interested in the java source.
I anticipate several enhancements such as:
Constant filtering in the
tableQuery()'s; e.g. I never want to see the access log information about
.png's that were delivered to web browsers, or I only want to see .zips that
were downloaded, etc...)
Enhanced table smarts; e.g. when a new query is
performed, retain the column order and column width that were present in the
previous query.